Logarithmic Loss
What is LogLoss?
LogLoss is an error calculation used to determine how close the predictions of a model are to the actual values.
When could you use it?
LogLoss can used for classification models that output a probability score.
Should it be big or small?
The goal is to reduce LogLoss when using it as a measure of model performance. A model that perfectly predicts probabilities would have a LogLoss of 0.
Why would you use this instead of accuracy?
Unlike accuracy, LogLoss is robust in the presence of imbalanced classes. It takes into account the certainty of the prediction.
Wait….how can accuracy be inaccurate?
When the target class has a large imbalance, for example 1% of the target class, then this can make accuracy dubious to interpret.
For example, let’s say you have a dataset with 10,000 rows and only 100 are the target. Then you could technically classify the whole set as “not the target” and get an accuracy of 99% - which while technically correct, isn’t very useful.
There are other ways to get around this like precision, recall and their harmonic mean (F1 score), but LogLoss is a more direct measure of what you are attempting to achieve - accurate probabilities.
What does LogLoss really measure?
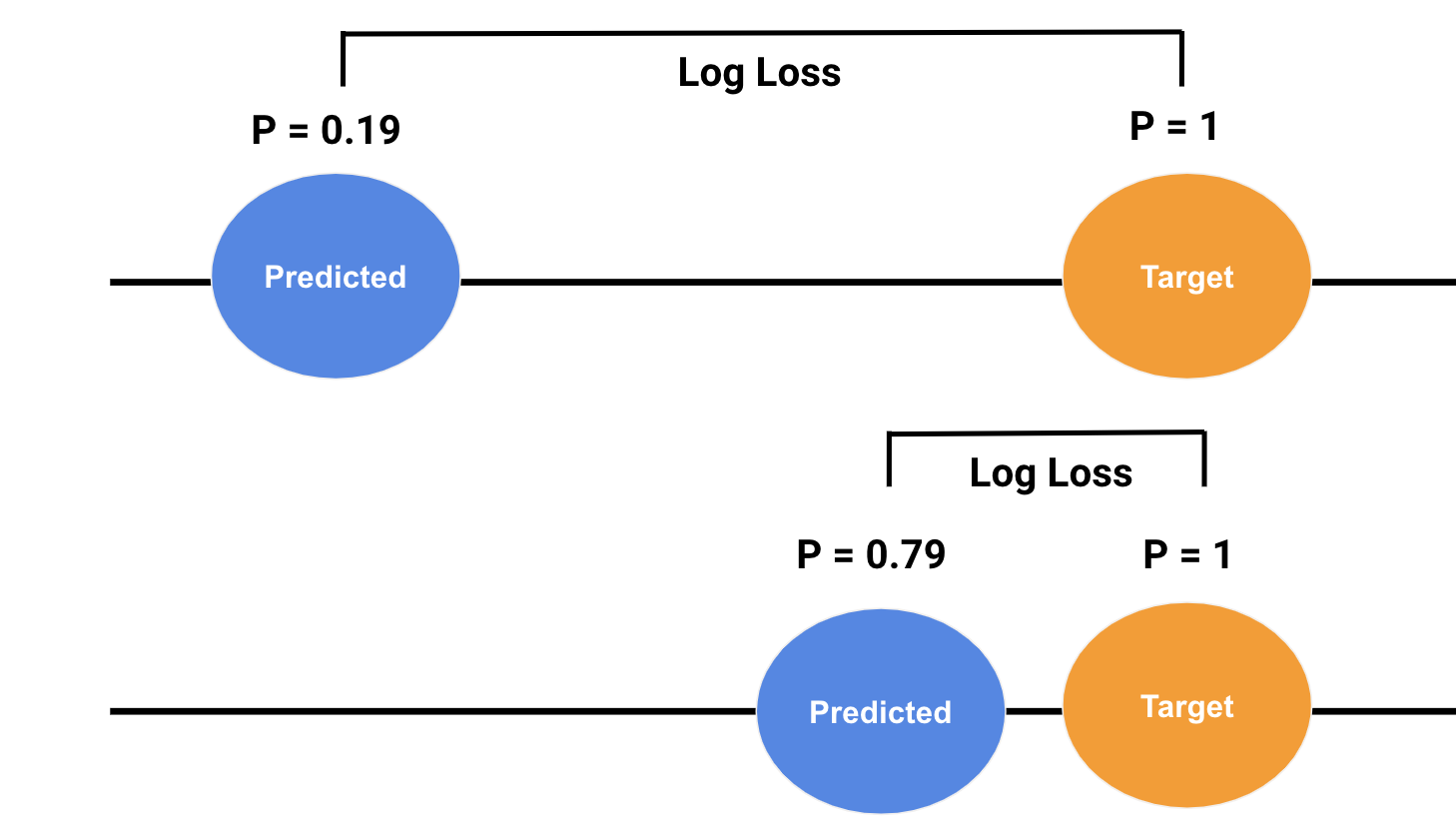
Below you can see a representation of predicted and actual probabilities.
The top example depicts a poor prediction, where there is a large difference between the predicted and actual, this is results in a large LogLoss. This is good because the function is penalizing a wrong answer that the model is “confident” about.
Conversely, the bottom example shows a good prediction that is close to the actual probability. This results in a low LogLoss, which is good because the model is rewarding a correct answer that the model is “confident” about.
Formula
Below is the formula for LogLoss from wikipedia. It is calculated for every observation in the dataset and then averaged.
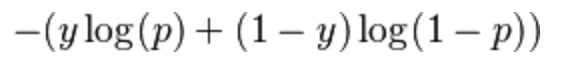
Simple right?
So, this all seems neat and simple. However, when I learned about it I became curious about two questions:
What does the distribution of LogLoss look like?
Why do we take the mean? Is that really the right choice?
Experiment 1: What does the distribution of LogLoss look like?
I decided to look into it by creating two models (one good, one bad) on a famous data science dataset called the Titanic dataset.
Specifically, I wanted to see what the distributions looked like for a good and poor predictive model.
You can find all of the code I used to create these models on my Github site, the modeling itself will not be the focus of this posting.
General characteristics of the two models.
- I used random forests to create both of the models.
- The “Good” model had engineered features and lots of trees.
- The “Poor” model had reduced features and some noise columns added in.
Good Model stats
FALSE
FALSE Call:
FALSE randomForest(formula = Survived ~ ., data = Boat3, mtyr = 10, ntree = 10000)
FALSE Type of random forest: classification
FALSE Number of trees: 10000
FALSE No. of variables tried at each split: 2
FALSE
FALSE OOB estimate of error rate: 16.39%
FALSE Confusion matrix:
FALSE 0 1 class.error
FALSE 0 506 43 0.07832423
FALSE 1 103 239 0.30116959Poor Model stats
FALSE
FALSE Call:
FALSE randomForest(formula = Survived ~ ., data = Boat4, mtyr = 10, ntree = 1000)
FALSE Type of random forest: classification
FALSE Number of trees: 1000
FALSE No. of variables tried at each split: 2
FALSE
FALSE OOB estimate of error rate: 30.42%
FALSE Confusion matrix:
FALSE 0 1 class.error
FALSE 0 459 90 0.1639344
FALSE 1 181 161 0.5292398You can see the OOB error rate is almost twice as high in “Poor” model.
Distributions
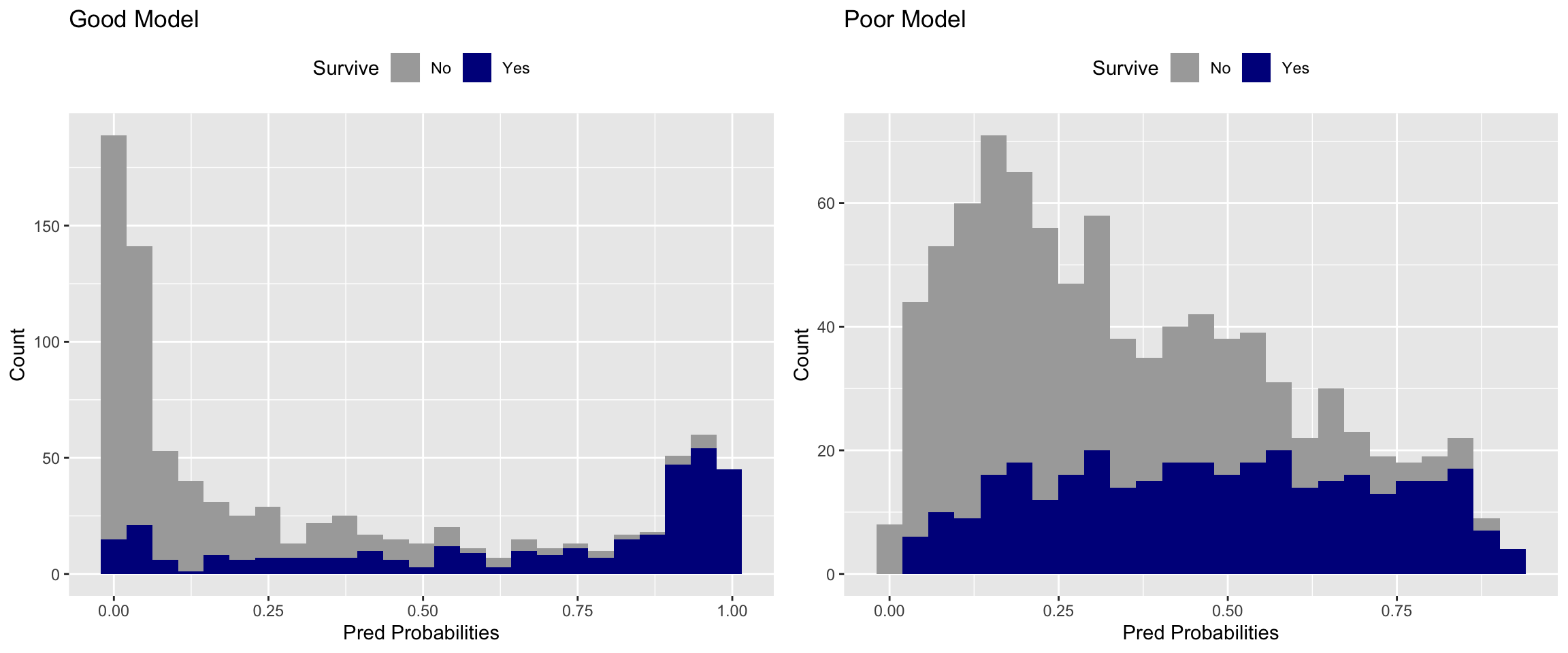
First I wanted to see the predicted probability distributions for the two hypothetical models.
Probabilities
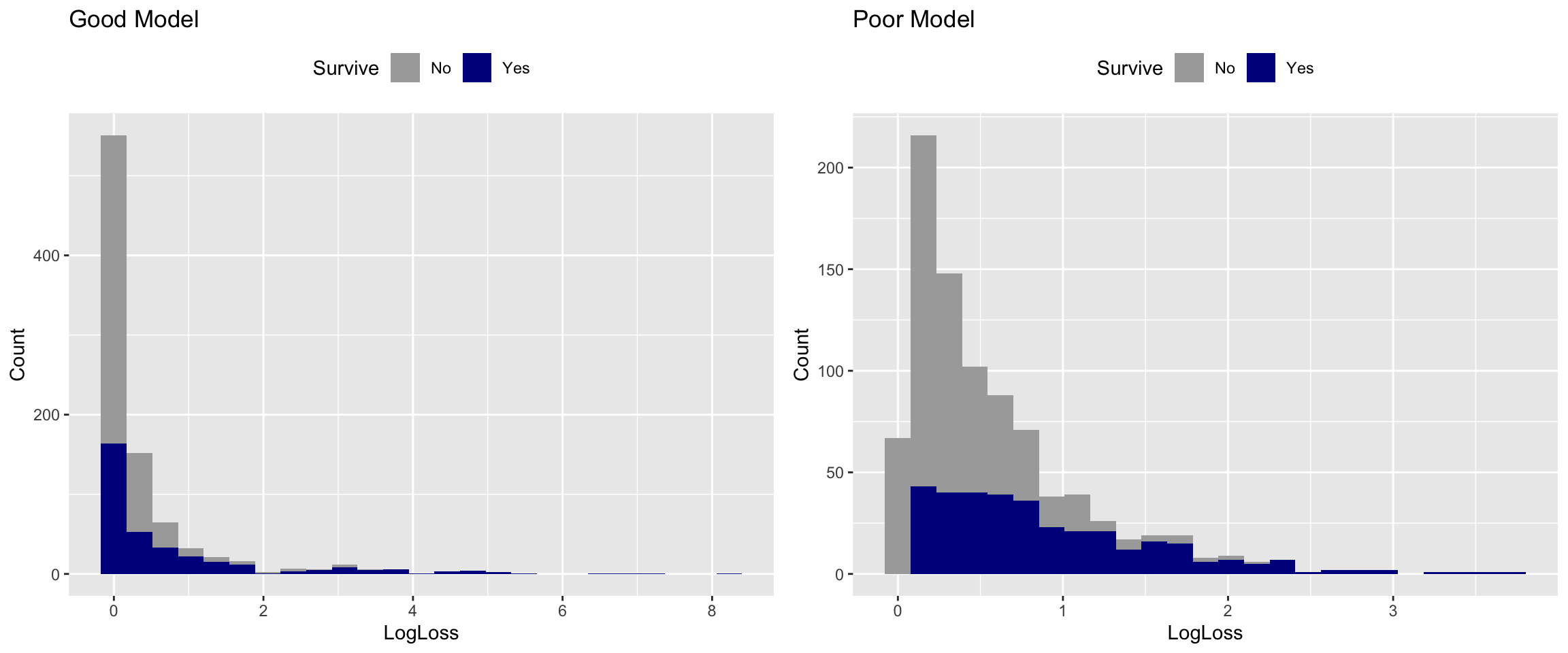
Then I wanted to plot the actual LogLoss distributions for the “Good” and “Poor” models.
LogLoss
Experiment 2: What’s in an average?
The distributions for the “Good” and “Poor” LogLoss are both skewed, which makes sense when you look back at the formula.
If it isn’t a normal distribution, then why use the average at all?
Before we get carried away, let’s do the math for the mean, standard deviation and median.
| Model | Mean | SD | Median |
|---|---|---|---|
| Good | 0.4523643 | 0.9512325 | 0.0887679 |
| Poor | 0.5944586 | 0.5703845 | 0.3989077 |
You can see above that the standard deviation (or spread) of the LogLoss is greater than the mean in the “Good” model and almost as large as the mean in the “Poor” model. This - combined with the shape of the distributions tells me that the mean may not be the best representation of LogLoss.
If you look at the last column, Median, these values appear to represent the distributions better.
Experiment 3: What about calculating LogLoss for each class?
The last two analyses lead me to ask another question.
Can we get median LogLoss for each class for each model and use them for comparison?
| Survive | Good_LogLoss | Poor_LogLoss | Perc_Diff_LogLoss |
|---|---|---|---|
| No | 0.0540372 | 0.2732933 | 0.6698307 |
| Yes | 0.1856526 | 0.7405439 | 0.5991076 |
It turns out that you can do that. The “Good” model had a better LogLoss for both the minority and majority class. This is a viable way to compare model performance in classification problems, and should be used over techniques like accuracy
Conclusions
LogLoss reflects performance of “Good” vs. “Poor” models.
The median may be a better choice than the average.
You can segment LogLoss down even further to look at the target and non-target class. This can tell you if the model is succeeding or failing at predicting one of the variable classes.